College of Engineering Unit:
A growing area of hardware security is the field of side channel analysis (SCA). SCA centers around attempting to deduce cryptographic secrets of a chip using information that is "leaked" out of the CPU. In the case of our project advisor, Vincent Immler, this information is electromagnetic waves that were captured using an oscilloscope. Analyzing the statistical properties of this information can ultimately yield secret information, such as private keys used in cryptography.
There are several existing Python libraries built for this domain, but each have their own issues. The datasets collected for observation can be quite large, on the order of terabytes, and the existing libraries were too slow for Vincent's liking. Additionally, they required that the data files be structured in a way that was not user friendly at all. Vincent proposed this project to design a library that could remedy both of these issues.
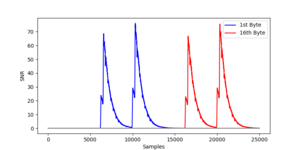
Our team's first task was to select a file format that was user friendly and could provide the speed we were looking for. We ran benchmarks between three different formats (DB, HDF5 and Zarr) and eventually settled on Zarr due to its speed of access and ease of use. Next, we implemented basic statistical functions such as mean, variance and others. These properties served as the foundation for more advanced properties specific to SCA such as the Signal to Noise Ratio (SNR) and Correlation Power Analysis (CPA). The code for these functions needed to be as optimized as possible, and it should ultimately be able to run in Jupyter notebooks.
We used several tools to build our library, in addition to the file format of Zarr. The core computations were handled with the Numpy scientific computing library. Numpy allowed us to easily write vectorized code that was faster than pure native Python. We also used the Numba and Python Multiprocessing libraries to take advantage of parallelization within our code. Finally, we used the Matplotlib library to visualize results and create graphs of the properties we calculated.
Ultimately, our framework provides an easy to use file format for storing data, and its speed matches or exceeds that of the commercial libraries. Our team is excited to see it used in real world research, and we are interested to see if future developers will work to expand our library even further.